
We have a framework written using spark scala api for file ingestion. We are using cloud composer also knows as airflow for our job orchestration. And so we wanted to perform following task with airflow (composer)
- First it will create a cluster with the provided configuration
- inserts the jar while creating a cluster
- creates a job and executes the job with given parameter
Good thing is airflow has a operator to execute jar file. However, the example available on airflow website is very specific to AWS envionment and so it took some time for me to figure out how to create dag for GCP databricks.
Let’s understand how to do this.
Setup Databricks Connection
To setup connection you need two things. databricks API token and databricks workspace URL.
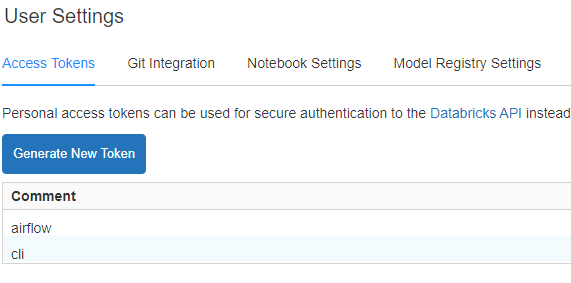
Generate API Token
To generate databricks API token, login to your workspace and then go to settings –> user settings. And then click on generate new token. Please save this token as you won’t be able to retrieve this again.
Following tasks you need to execute on Airflow (cloud composer). You will need admin access for this.
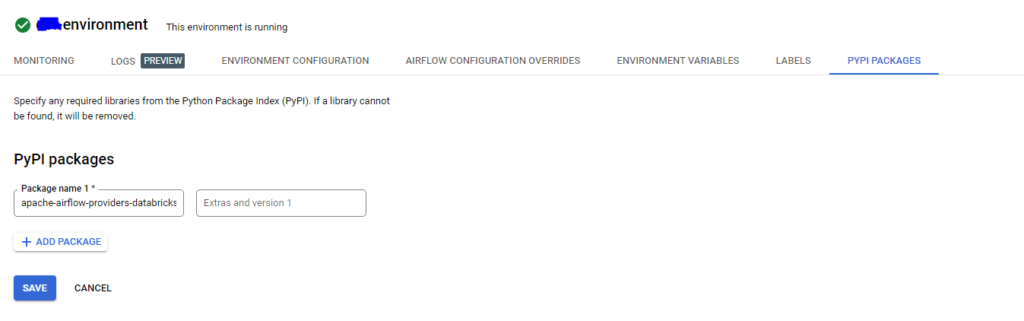
Install Databricks Library
- from your google cloud console, navigate to your cloud composer instance and click on it.
- Click on PYPI PACKAGES and then click on EDIT.
- Add the apache-airflow-providers-databricks package
- it will take some time to make this changes, so wait for some time and visit this page again to see if package has installed properly. (internet connectivity from cloud could create an issue for this installation)
Create Connection
Login to airflow and navigate to admin –> connection. We are just modifying default connectoin, so if you were able to install the databricks package sucessfully. You should be able to see databricks_default connection. Click on edit. You just need to fill following fields.
- Host: you’re host should be databricks workspace URL, it should look something like this.
https://xxx.gcp.databricks.com/?o=xxx - Password: In password field you need to paste the API token we created in first step.
Now let’s write DAG to create cluster and execute the jar file.
DAG to Execute JAR on Databricks
import os
from datetime import datetime
from airflow import DAG
from airflow.providers.databricks.operators.databricks import DatabricksSubmitRunOperator
from airflow.models import Variable
with DAG(
dag_id='ingest_csv_file_to_bigqury',
schedule_interval='@daily',
start_date=datetime(2021, 1, 1),
tags=['Gaurang'],
catchup=False,
) as dag:
new_cluster = {
"spark_version": "7.3.x-scala2.12",
"node_type_id": "n1-standard-4",
"autoscale": {
"min_workers": 2,
"max_workers": 8
},
"gcp_attributes": {
"use_preemptible_executors": False,
"google_service_account": "sa-databricks@testproject.iam.gserviceaccount.com"
},
}
spark_jar_task = DatabricksSubmitRunOperator(
task_id='run_ingestion_jar',
new_cluster=new_cluster,
spark_jar_task={'main_class_name': 'com.test.Main', "parameters":["xxx", "yyy]},
libraries=[{'jar': 'gs://deploymet/test-1.0.jar'}],
)
spark_jar_task
DatabricksSubmitRunOperator takes three parmeters.
- new_cluster: You need to provide a JSON for creating new cluster.
- spark_jar_task: you need to provide you main class and parameters your jar is expecting
- libraries: location of your jar file.