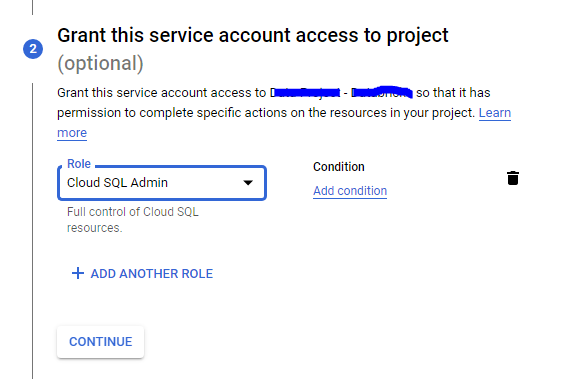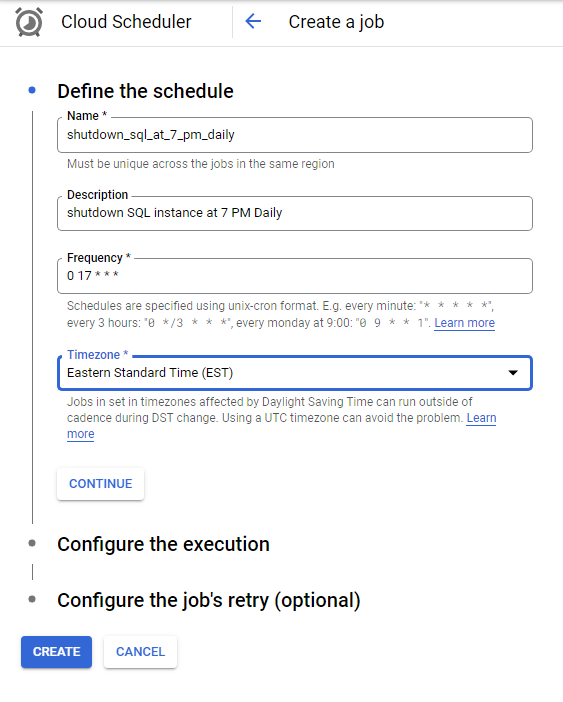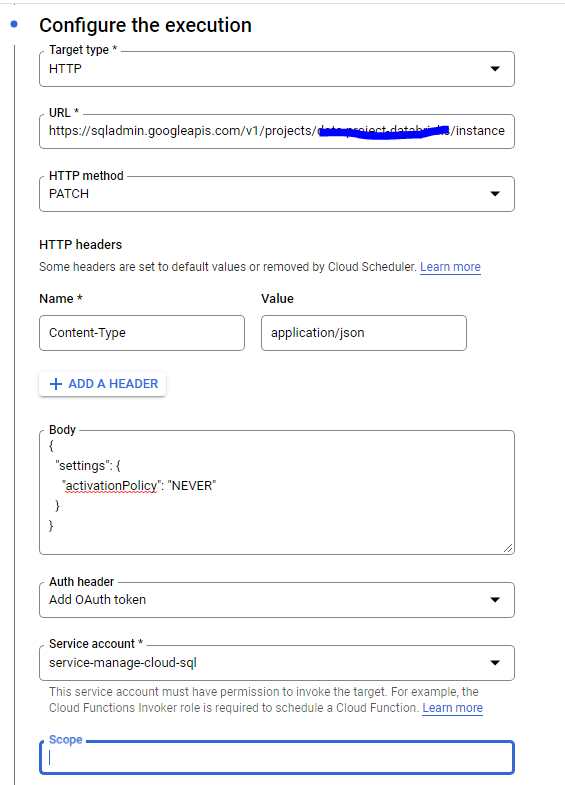
Currently I am helping an organization to adopt Google Cloud Platform. And though we have decided to use terraform for infrastructure as code, some people are creating/modifying resources directly through console. And so what we wanted to in some auditability and notification around resource creation or modification.
With GCP all the audit logs are available in google cloud logging. However, cloud logging is costly and not a good idea to store log for a longer period of time. The other reason is query format for logging is bit different and not everyone is familiar with that.
Audit
For Audit Purpose I am configuring the GCP Log Router to redirect the logs to bigquery.
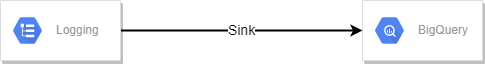
Query
Query is only looking for any modification done by any user rather than service account.
protoPayload.@type="type.googleapis.com/google.cloud.audit.AuditLog"
protoPayload.authenticationInfo.principalSubject:"user:"
proto_payload.method_name: ("delete" OR "create" OR "update")
Make sure to choose Use partitioned tables else it will create a table for day.
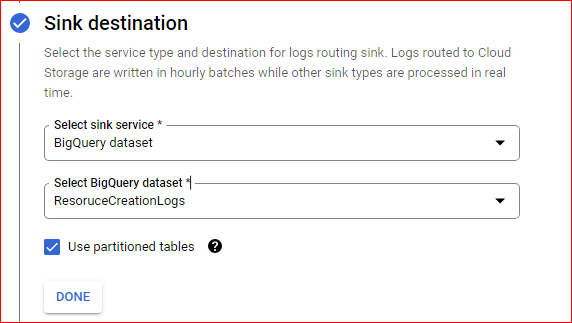
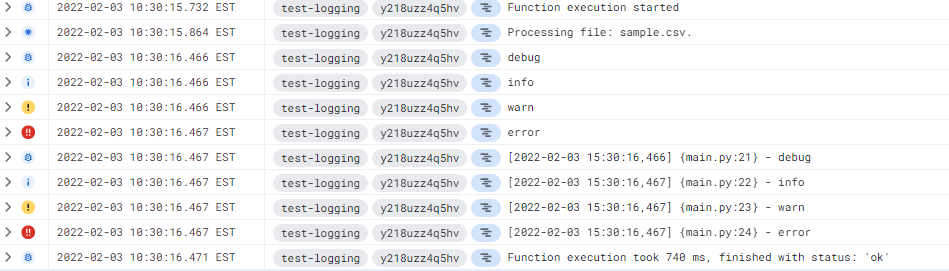
Once you configure the sink, you will be able to see all the logs for any resource modification.
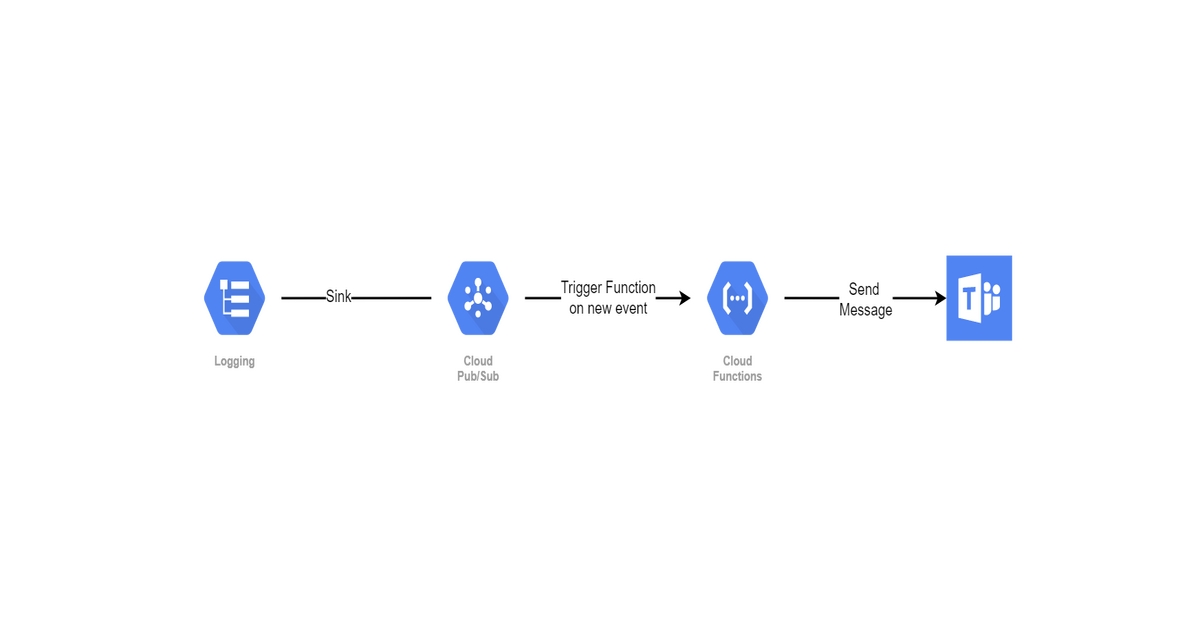
Notification

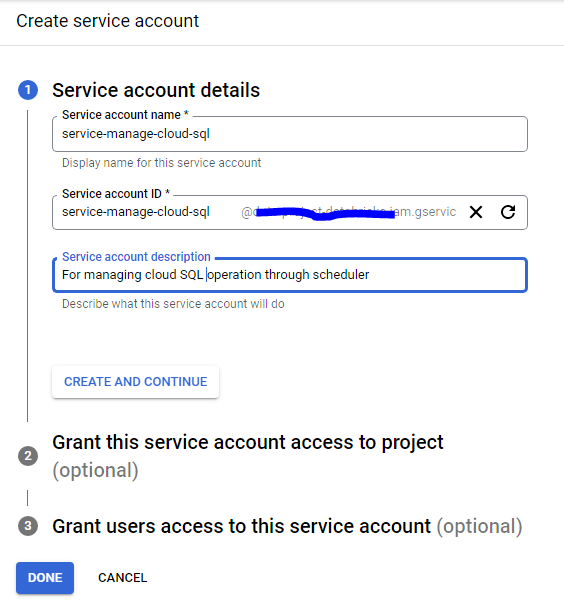
GCP does not have any direct integration available with Microsoft teams ( may be coz it’s Microsoft product :)). And so I needed to write my own cloud function which can send message to teams’ channel.
For this as well we need to create sink with similar query. However, rather than sending logs to bigquery we are sending logs to PubSub topic.
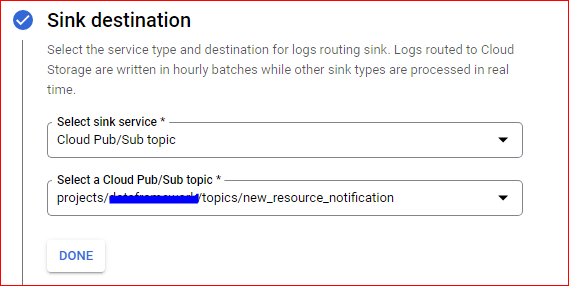
Once Sink is created we need to create a cloud function to trigger when event appears on this topic.

Code
import base64
import json
import os
import requests
from pprint import pprint
def func_handler(event, context):
"""Triggered from a message on a Cloud Pub/Sub topic.
Args:
event (dict): Event payload.
context (google.cloud.functions.Context): Metadata for the event.
"""
message = json.loads(base64.b64decode(event['data']).decode('utf-8'))
pprint(message)
print(type(message))
resource_type = message.get("resource").get("type")
project_id = message.get("resource").get("labels").get("project_id")
region = message.get("resource").get("labels").get("region")
method = message.get("protoPayload").get("methodName").lower()
user = message.get("protoPayload").get("authenticationInfo").get("principalEmail")
resource_name = message.get("protoPayload").get("resourceName").split("/")[-1]
if "create" in method:
action = "created"
elif "update" in method:
action = "updated"
elif "delete" in method:
action = "deleted"
else:
action= method
title = "{} got {}".format(resource_type, action)
content="""
Resource Name: {}
Project ID: {}
Region: {}
Action: {}
User: {}
""".format(resource_name, project_id, region, action, user)
webhook = os.environ.get("webhook")
send_teams(webhook, content, title)
def send_teams(webhook_url:str, content:str, title:str, color:str="FF0000") -> int:
"""
- Send a teams notification to the desired webhook_url
- Returns the status code of the HTTP request
- webhook_url : the url you got from the teams webhook configuration
- content : your formatted notification content
- title : the message that'll be displayed as title, and on phone notifications
- color (optional) : hexadecimal code of the notification's top line color, default corresponds to black
"""
response = requests.post(
url=webhook_url,
headers={"Content-Type": "application/json"},
json={
"themeColor": color,
"summary": title,
"sections": [{
"activityTitle": title,
"activitySubtitle": content
}],
},
)
print(response.status_code) # Should be 200
Leave a Comment