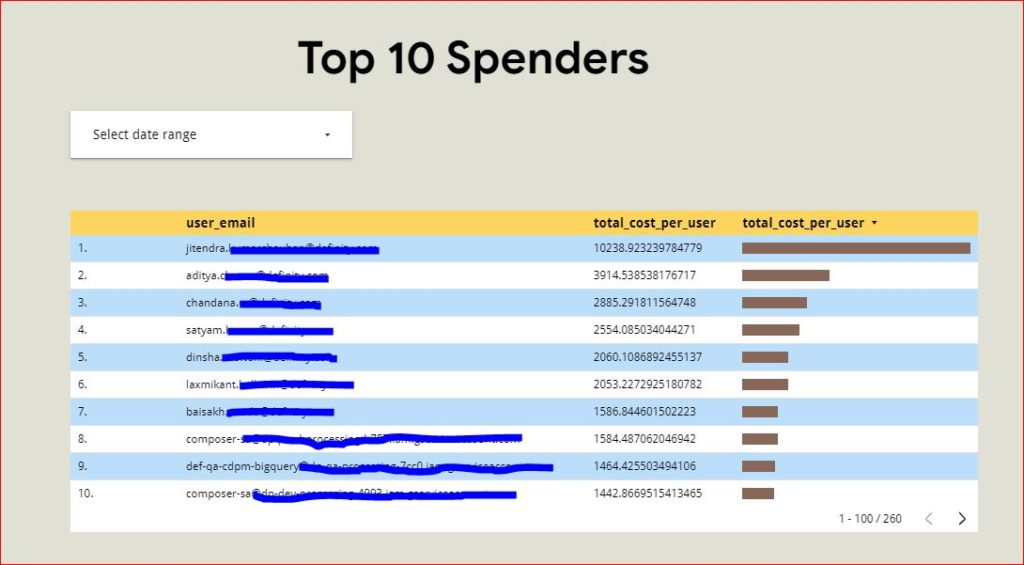
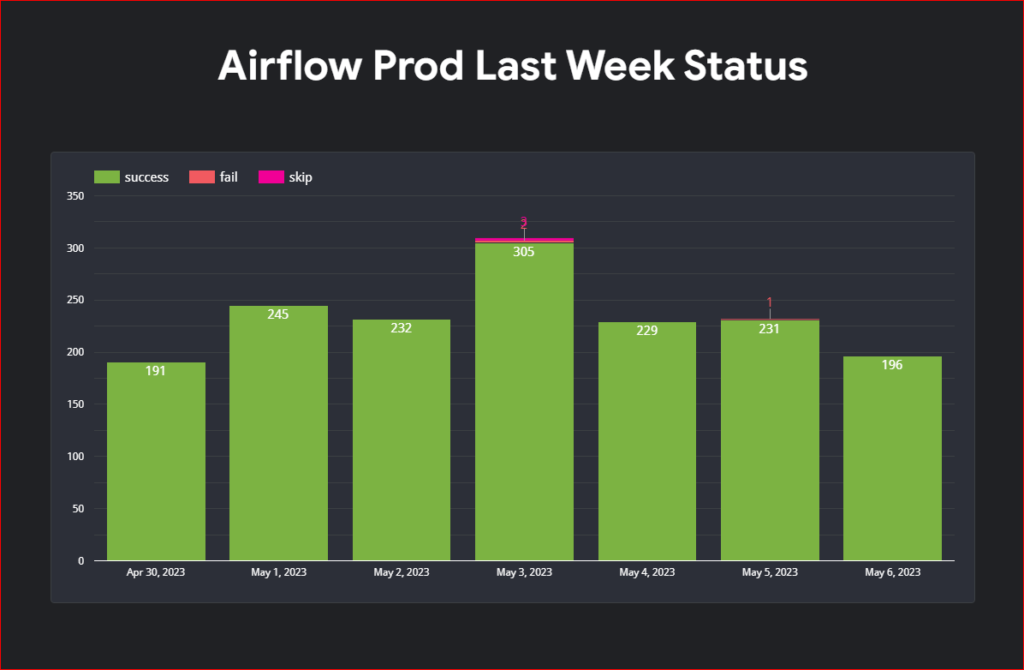
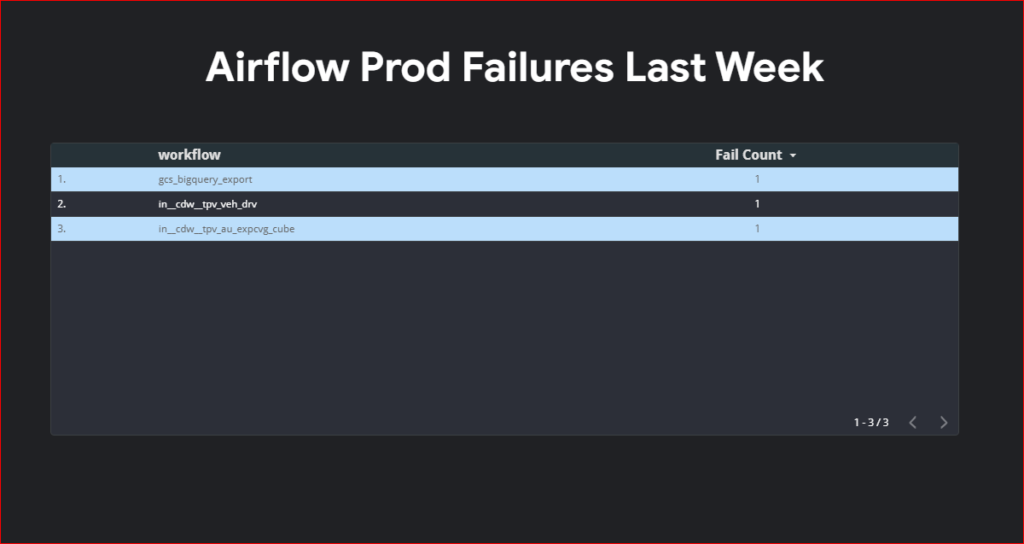
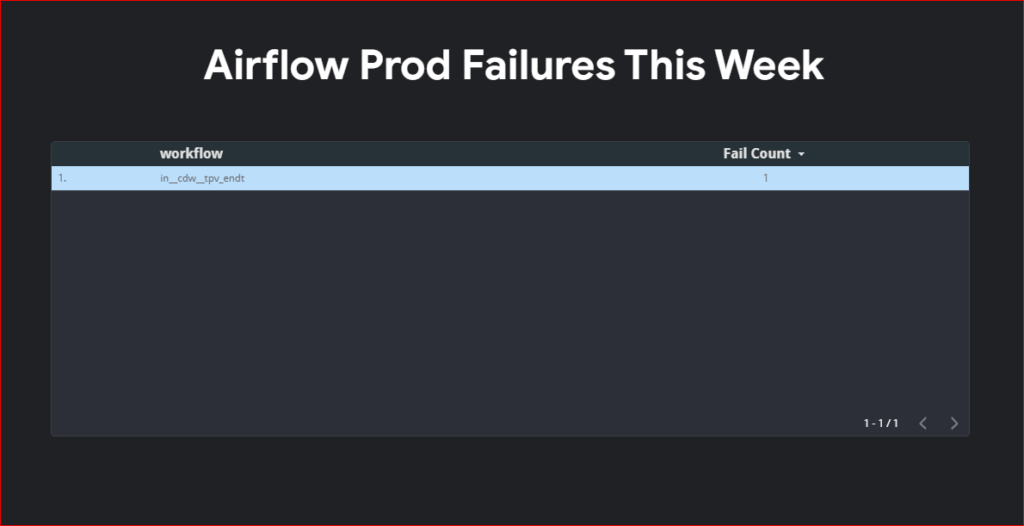
In today’s data-driven landscape, organizations often have multiple teams comprising domain experts who create their own unique products. However, enabling other teams to leverage these products efficiently requires a structured approach. Enter data mesh—a paradigm that decentralizes data ownership and processing. In this guide, we’ll explore how to implement data mesh using Google Cloud Platform (GCP) BigQuery, empowering teams to manage their data products seamlessly.
Setting up Domain-Specific GCP Projects
Begin by assigning a dedicated GCP project to each domain or business team. This ensures that teams have the autonomy to develop and manage their data products within their respective environments. By segregating projects based on domains, teams can focus on their specific requirements without interfering with others’ workflows.
Development and Promotion Workflow
Within their assigned GCP projects, domain teams develop their data products tailored to their expertise. These products undergo rigorous testing and refinement in the development environment. However, it’s crucial to avoid publishing directly from the development environment to prevent potential disruptions for subscribers. Frequent changes in the development phase can lead to compatibility issues and operational challenges for downstream users.
Promotion to Higher Environments
Once a data product is deemed ready for consumption, it’s promoted to higher environments, typically housed in different GCP projects. This transition ensures that only validated and stable versions of products are made available to subscribers. By segregating development and production environments, organizations can maintain data integrity and stability while minimizing disruptions to subscriber workflows.
Publishing Data Products
When promoting a data product to a higher environment, a team lead assumes the responsibility of publishing it. This involves orchestrating a seamless transition and ensuring that subscribers can access the updated version without interruptions.
Make sure Analytics Hub API is enabled for this.
Follow these steps to publish your product:
- Navigate to GCP BigQuery and access Analytics Hub. Click on “Create Exchange.”
- Depending on the nature of your product, provide the necessary details and proceed by clicking “Create Exchange.”
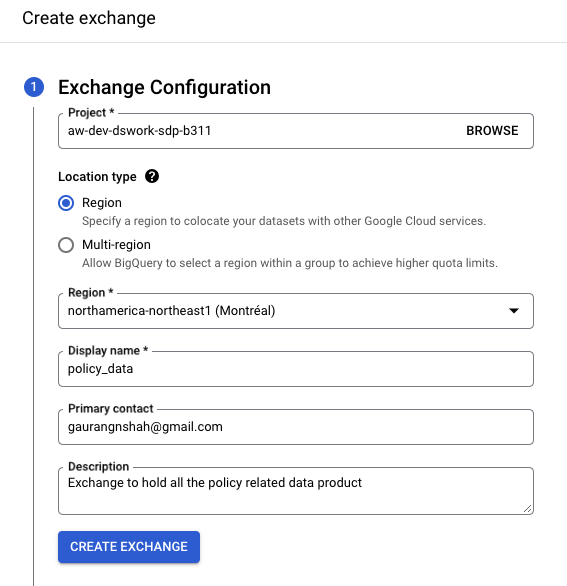
- At this stage, you’ll have the option to configure permissions for administration, publishing, subscription, and viewing of the listing. You can either set these permissions now or configure them later.
- Once the exchange is created, proceed to create a listing for it. A listing involves selecting the dataset you wish to publish. Currently, GCP BigQuery only allows choosing datasets only. And depends on what location you choose for your exchange you should be able to select datasets.
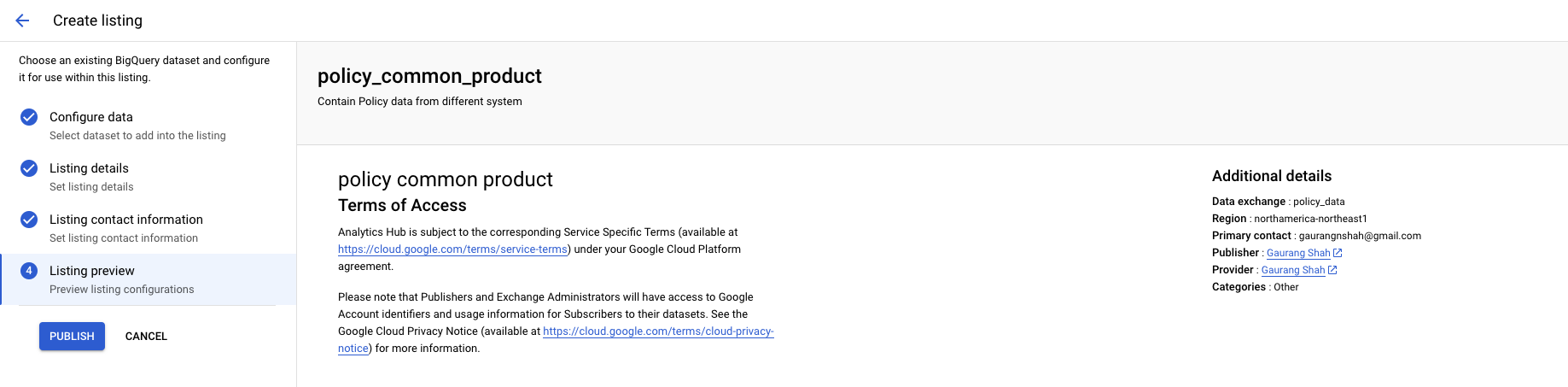
- Provide the required Listing Details and Listing Contact Information corresponding to your data product. Once completed, you’ll be able to publish the dataset through the listing.
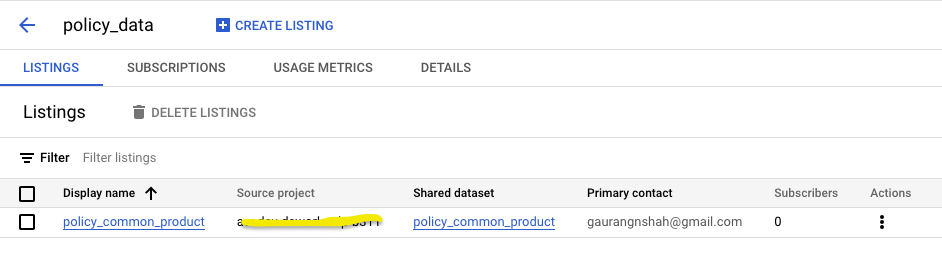
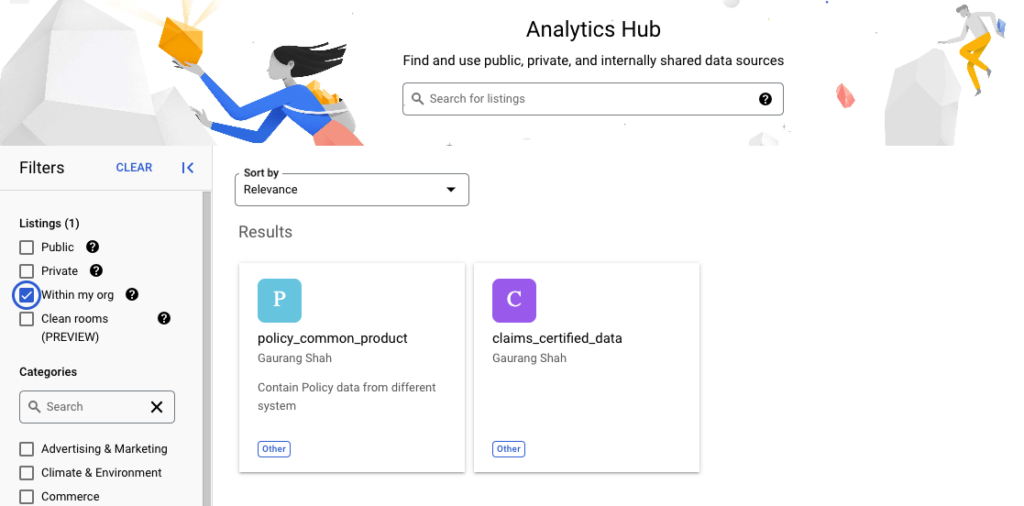
Subscribing to the Data Products (listings)
- Once the Data Product is published other users can search and subscribe to this listing. User would need access to create a new Dataset in the project they want to subscribe this new data products.