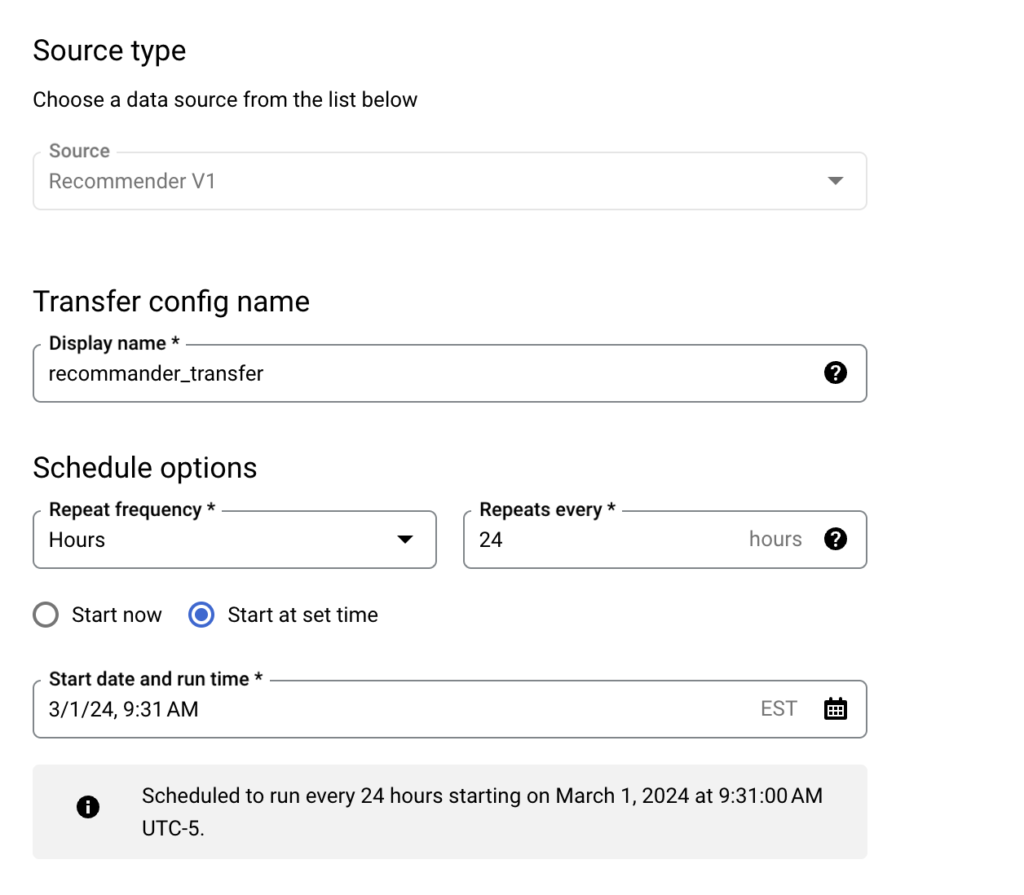
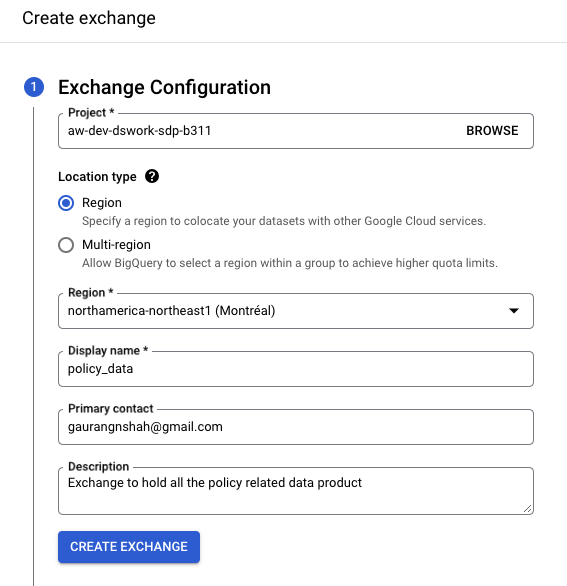
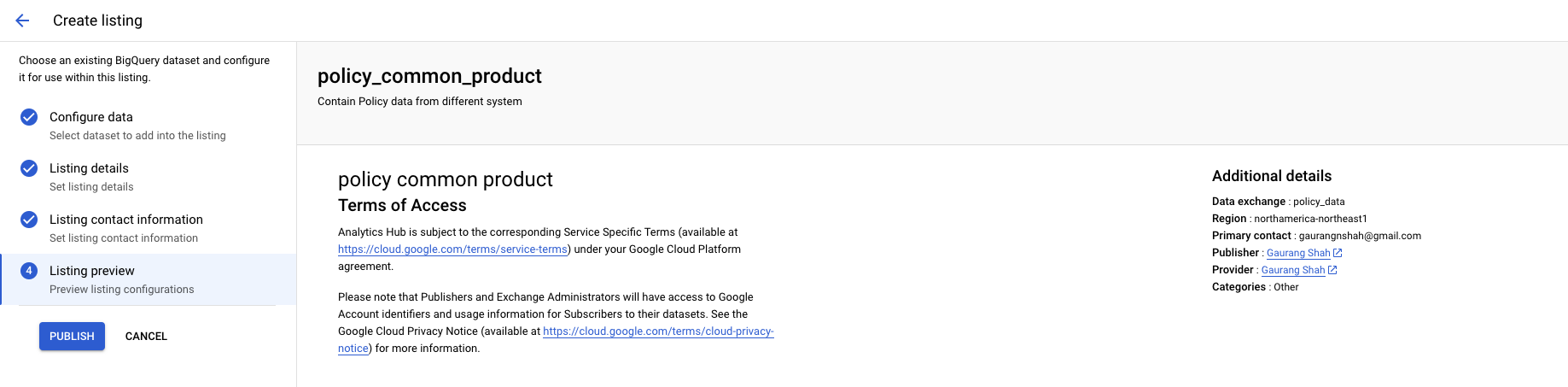
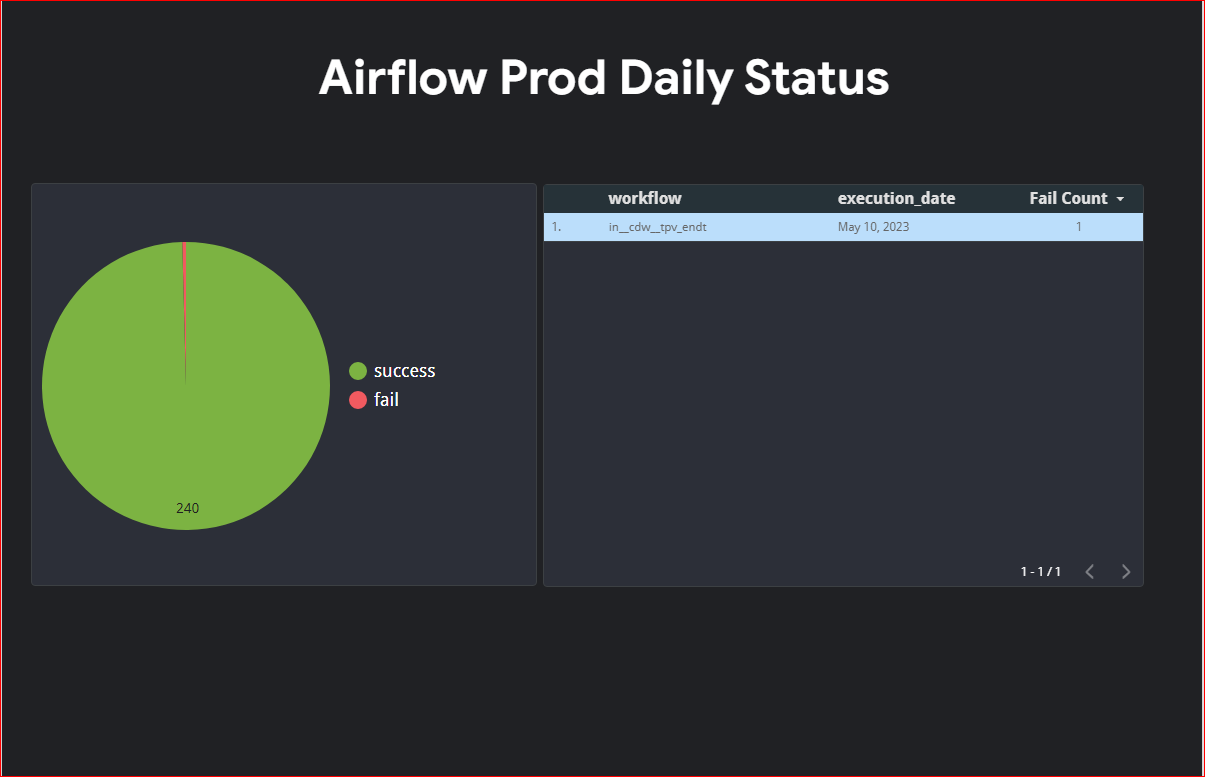
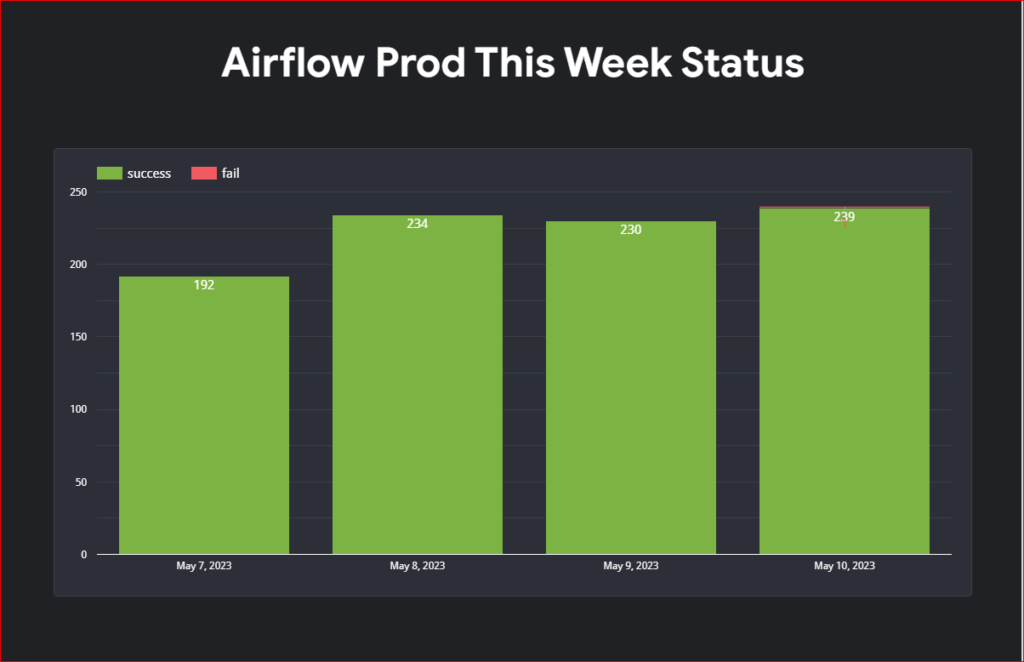
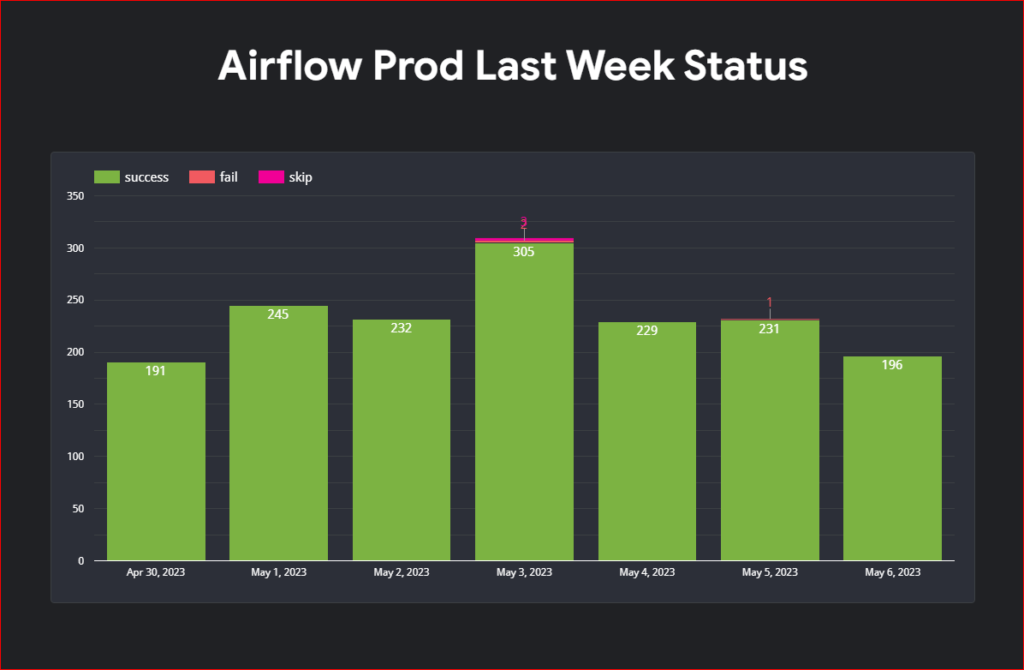
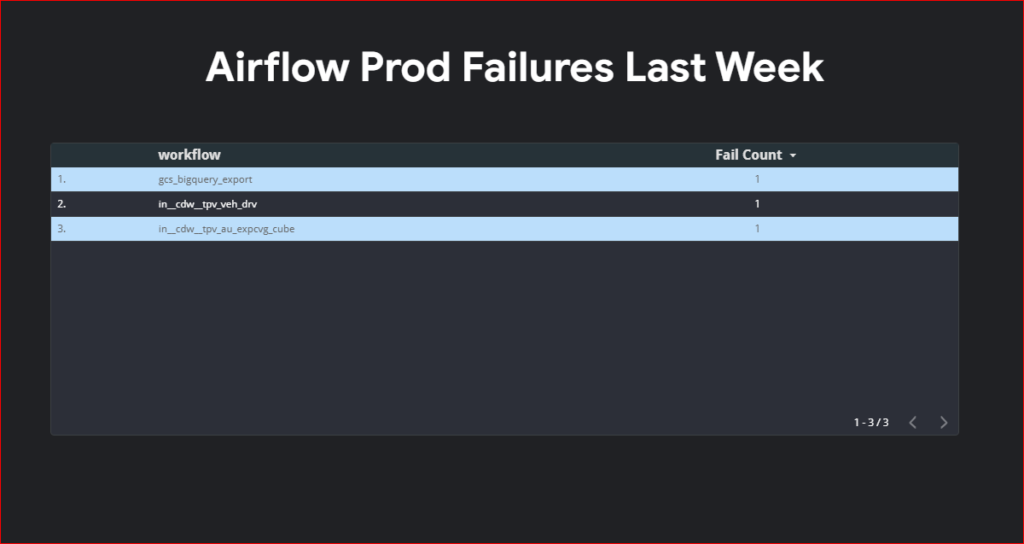
Airflow providers multiple secrets backends to be configured for storing airflow connection and variables. for a long time we were using airflow backends however recently I migrated all the connection to vault and started using vault as our backend. In this post I will show you a step by step guide on how to do this.
Configure HashiCorp Vault
create mount point
we have multiple composer(airflow) environment and so strategy we have used is created a single mount point named airflow and then use the different path for different airflow instances. you could choose to have different strategy as per your organization standard and requirement. Run the following command to create the secrets mount point.
vault secrets enable -path=airflow -version=2 kv
Create role
vault provides multiple ways to authenticate, what we are going to use is role. so let’s create a role. please copy the secret id from the output and store it somewhere. this would be useful when we will vault connection in airflow.
vault write auth/approle/role/gcp_composer_role \
role_id=gcp_composer_role \
secret_id_ttl=0 \
secret_id_num_uses=0 \
token_num_uses=0 \
token_ttl=24h \
token_max_ttl=24h \
token_policies=gcp_composer_policy
Create Policy
role need to be associated with a policy. policy is nothing but a grant (access). Run the following code to create a policy which would give read and list permission to airflow path, we created earlier.
vault policy write gcp_composer_policy - <<EOF
path "airflow/*" {
capabilities = ["read", "list"]
}
EOF
now are are all set in vault. let’s change the airflow configuration to start using vault.
Configure Airflow (GCP Cloud Composer)
Navigate to your airflow instances and override following two settings.
- secrets.backend =
airflow.providers.hashicorp.secrets.vault.VaultBackend - secrets.backend_kwargs
{
"mount_point": "airflow",
"connections_path": "dev-composer/connections" ,
"variables_path": null,
"config_path": null,
"url": "<your_vault_url>",
"auth_type": "approle",
"role_id":"gcp_composer_role",
"secret_id":"<your_secret_id>"
}
connection_path: path where you would like to store your airflow connection. for me it’s my composer name and then connection. if you have single airflow you could just store everything under connection.
variables_path: i have specified null as I am storing variables in airflow. if you want to store variables also in vault, just provide the path.
config_path: same as variables, I am keeping config in airflow
url: replace with you vault url
auth_type: we are using approle to authenticate with vault as discussed above
role_id: the role we created above. if you have used different name, please replace here.
secret_id: secret_id we generated for the role
How to store connections
for connection create a path with connection name and put the json with proper key and value for connection. for example, default bigquery connection. it would look like this.
mount point: airflow
Path: dev-composer/connections/bigquery_default
{
"conn_type": "google_cloud_platform",
"description": "",
"extra": "{\"extra__google_cloud_platform__project\": \"youre_project\", \"extra__google_cloud_platform__key_path\": \"\", \"extra__google_cloud_platform__key_secret_name\": \"\", \"extra__google_cloud_platform__keyfile_dict\": \"\", \"extra__google_cloud_platform__num_retries\": 5, \"extra__google_cloud_platform__scope\": \"\"}",
"host": "",
"login": "",
"password": null,
"port": null,
"schema": ""
}
How to store variables
for variables. in the json key would alway be value. as shows below
mount point: airflow
path: dev-composer/variables/raw_project_name
{
"value": "raw_project_id"
}
Leave a Comment