Few months back our organization decided to go with GCP for data platform. And so we started evaluating multiple tools to bring data from different RDMBS sources. Our goal was to find a tool which helps us identify CDC from multiple sources we have (MySQL, oracle, sql server, db2 on mainframe) and bring it to either cloud storage or bigquery.
And by the time I am writing this blog, GCP doesn’t have any tool which satisfies our requirement. It has data stream but it only supports oracle and MySQL. And while searching outside GCP I stumbled upon Debezium. Debezium is a open source tool which help identify CDC from multiple RDBMS sources and puts the data on Kafka or pubsub topics in real-time. Much better, we were looking for some batch solution and we found streaming.
In this blogpost, I will explain in details how to deploy Debezium on GCP Kubernatees cluster and connect that to gcp cloudsql and gcp pubsub topics.
Deploying Debezium on GCP Kubernatees
Create Service Accounts
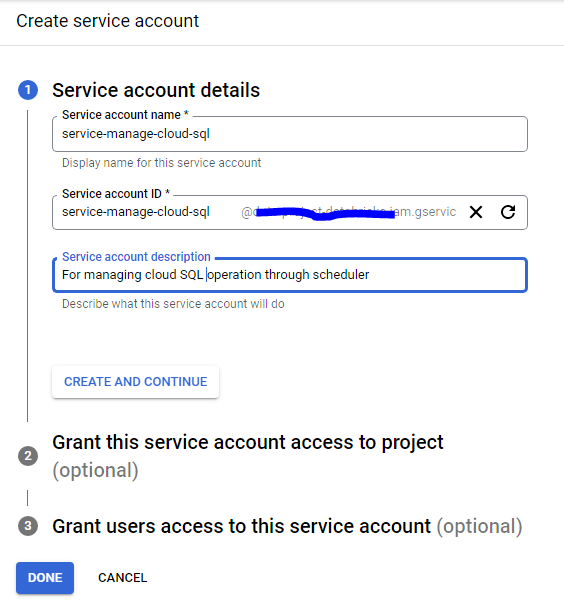
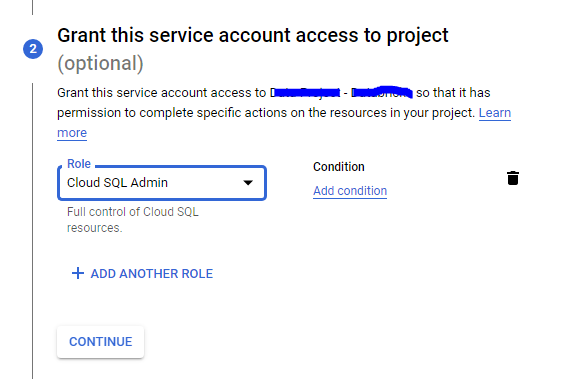
To deploy debezium on kubernatees we first need to create an I Am service account. create a service account with following roles.
- Cloud SQL Client
- Pub/Sub Publisher
You will also need to create a service account for pods. use the following command line from to create service account.
kubectl apply -f - <<EOF apiVersion: v1 kind: ServiceAccount metadata: name: debezium-sa EOF
Create MySQL User
considering you already have a cloud sql (mysql) instance running. let’s create a user with proper access to read transaction logs.
CREATE USER 'replication_user'@'%' IDENTIFIED BY 'secret'; GRANT SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'replication_user'
Create GCP Kubernetes cluster for Debezium
gcloud beta container clusters create "debezium-poc" --scopes=sql-admin,pubsub --region "us-east1" --service-account=sa-debzium-k8@dataframework.iam.gserviceaccount.com
now, once cluster is created we need to deploy pods and configuration for the pods.
Deploying config-map
mysql_config_map.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: debezium-mysql
labels:
app: debezium-mysql
data:
application.properties: |-
debezium.sink.type=pubsub
debezium.source.connector.class=io.debezium.connector.mysql.MySqlConnector
debezium.source.offset.storage.file.filename=data/offsets.dat
debezium.source.offset.flush.interval.ms=0
debezium.source.database.hostname=localhost
debezium.source.database.port=3306
debezium.source.database.user=replication_user
debezium.source.database.password=secret
debezium.source.database.server.id=184054
debezium.source.database.server.name=dpmysql
debezium.source.database.history = io.debezium.relational.history.FileDatabaseHistory
debezium.source.database.history.file.filename = history_file.txt
in above configuration. Please change user and password as per the user you have created. server.name could be anything which makes sense for you for the source. server.id needs to be a unique number so you can provide any random number.
To deploy the config map run the following command.
kubectl apply -f mysql_config_map.yamlDeploying StatefulSet
StatefulSet is consist of two containers.
- debezium server – While writing this blog 1.7.0.Final is the latest version available so I am using it. however, you can use whatever version is latest.
- cloud-sql-proxy – This is required to connect cloud sql instance from kubernetes.
mysql_statefulset.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: debezium-mysql
labels:
app: debezium-mysql
spec:
replicas: 1
serviceName: debezium-mysql
selector:
matchLabels:
app: debezium-mysql
template:
metadata:
labels:
app: debezium-mysql
version: v1
spec:
serviceAccountName: debezium-sa
securityContext:
fsGroup: 185 # Debezium container uses jboss user thats id is 185.
containers:
- name: debezium-server
image: debezium/server:1.7.0.Final
volumeMounts:
- name: debezium-config-volume
mountPath: /debezium/conf
- name: debezium-data-volume
mountPath: /debezium/data
- name: cloud-sql-proxy
image: gcr.io/cloudsql-docker/gce-proxy:1.27.1
command:
- /cloud_sql_proxy
- -instances=dataframework:us-east1:dpmysql-public=tcp:3306
securityContext:
runAsNonRoot: true
volumes:
- name: debezium-config-volume
configMap:
name: debezium-mysql
volumeClaimTemplates:
- metadata:
name: debezium-data-volume
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 10Mi
To deploy the Statefulset run following command
kubectl apply -f mysql_statefulset.yamlDeploying Service
the last thing we need to deploy is a service for our pods.
mysql_cdc_service.yaml
apiVersion: v1
kind: Service
metadata:
name: debezium-mysql
labels:
app: debezium-mysql
spec:
type: ClusterIP
ports:
- port: 8080
targetPort: 8080
protocol: TCP
name: http
clusterIP: None
selector:
app: debezium-mysql
To deploy service run the following command
kubectl apply -f mysql_cdc_service.yamlCreate PubSub Topic
so now, we have deployed the Debezium on Kubernetes, all we need is a pubsub topic created to capture all the changes.
The topic name should be in format: <server_name>. <database_name>.<table_name>
- server_name – this should be from your config map debezium.source.database.server.name property
- database_name – mysql database name
- table_name – mysql table name.